Event-Driven Visual Description¶
Robots process a massive amount of sensory data. Running a large Vision Language Model (VLM) on every single video frame to ask “What is happening?”, while possible with smallers models, is infact computationally expensive and redundant.
In this tutorial, we will use the Event-Driven nature of EmbodiedAgents to create a smart “Reflex-Cognition” loop. We will use a lightweight detector to monitor the scene efficiently (the Reflex), and only when a specific object (a person) is found, we will trigger a larger VLM to describe them (the Cognition). One can imagine that this description can be used for logging robot’s observations or parsed for triggering further actions downstream.
The Strategy: Reflex and Cognition¶
Reflex (Vision Component): A fast, lightweight object detector runs on every frame. It acts as a gatekeeper.
Event (The Trigger): We define a smart event that fires only when the detector finds a “person” (and hasn’t seen one recently).
Cognition (VLM Component): A more powerful VLM wakes up only when triggered by the event to describe the scene.
1. The Reflex: Vision Component¶
First, we set up the Vision component. This component is designed to be lightweight. By enabling the local classifier, we can run a small optimized model contained within the component, directly on the edge.
from agents.components import Vision
from agents.config import VisionConfig
from agents.ros import Topic
# Define Topics
camera_image = Topic(name="/image_raw", msg_type="Image")
detections = Topic(name="/detections", msg_type="Detections") # Output of Vision
# Setup the Vision Component (The Trigger)
# We use a lower threshold to ensure we catch people easily and we use a small embedded model
vision_config = VisionConfig(threshold=0.6, enable_local_classifier=True)
vision_detector = Vision(
inputs=[camera_image],
outputs=[detections],
trigger=camera_image, # Runs on every frame
config=vision_config,
component_name="eye_detector",
)
The trigger=camera_image argument tells this component to process every single message that arrives on the /image_raw topic.
2. The Trigger: Smart Events¶
Now, we need to bridge the gap between detection and description. We don’t want the VLM to fire 30 times a second just because a person is standing in the frame.
We use events.OnChangeContainsAny. This event type is perfect for state changes. It monitors a list inside a message (in this case, the labels list of the detections).
from agents.ros import Event
# Define the Event
# This event listens to the 'detections' topic.
# It triggers ONLY if the "labels" list inside the message contains "person"
# after not containing a person (within a 5 second interval).
event_person_detected = Event(
detections.msg.labels.contains_any(["person"]),
on_change=True, # Trigger only when a change has occurred to stop repeat triggering
keep_event_delay=5, # A delay in seconds
)
Note
keep_event_delay=5: This is a debouncing mechanism. It ensures that once the event triggers, it won’t trigger again for at least 5 seconds, even if the person remains in the frame. This prevents our VLM from being flooded with requests and can be quite useful to prevent jittery detections, which are common specially for mobile robots.
See also
Events can be used to create arbitrarily complex agent graphs. Check out all the events available in the Sugarcoat🍬 Documentation.
3. The Cognition: VLM Component¶
Finally, we set up the heavy lifter. We will use a VLM component powered by Qwen-VL running on Ollama.
Crucially, this component does not have a topic trigger like the vision detector. Instead, it is triggered by event_person_detected.
We also need to tell the VLM what to do when it wakes up. Since there is no user typing a question, we inject a FixedInput, a static prompt that acts as a standing order.
from agents.components import VLM
from agents.clients import OllamaClient
from agents.models import OllamaModel
from agents.ros import FixedInput
description_output = Topic(name="/description", msg_type="String") # Output of VLM
# Setup a model client for the component
qwen_vl = OllamaModel(name="qwen_vl", checkpoint="qwen2.5vl:7b")
ollama_client = OllamaClient(model=qwen_vl)
# We define a fixed prompt that is injected whenever the component runs.
fixed_prompt = FixedInput(
name="prompt",
msg_type="String",
fixed="A person has been detected. Describe their appearance briefly.",
)
visual_describer = VLM(
inputs=[fixed_prompt, camera_image], # Takes the fixed prompt + current image
outputs=[description_output],
model_client=ollama_client,
trigger=event_person_detected, # CRITICAL: Only runs when the event fires
component_name="visual_describer",
)
Launching the Application¶
We combine everything into a launcher.
from agents.ros import Launcher
# Launch
launcher = Launcher()
launcher.add_pkg(
components=[vision_detector, visual_describer],
multiprocessing=True,
package_name="automatika_embodied_agents",
)
launcher.bringup()
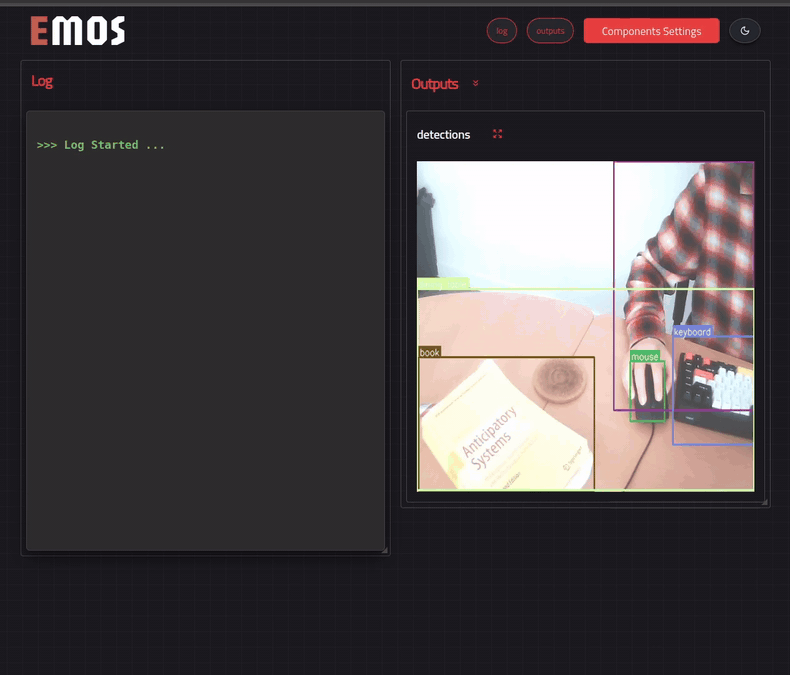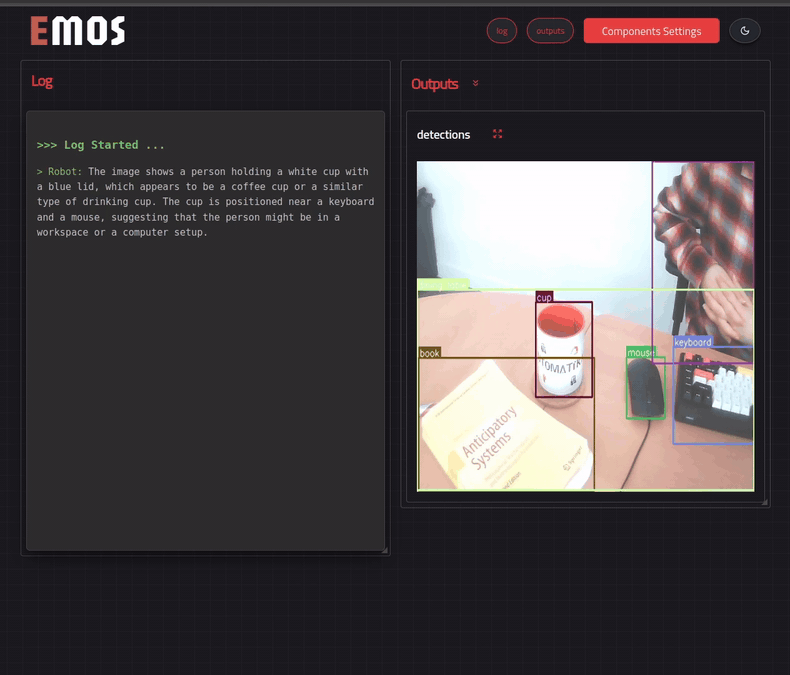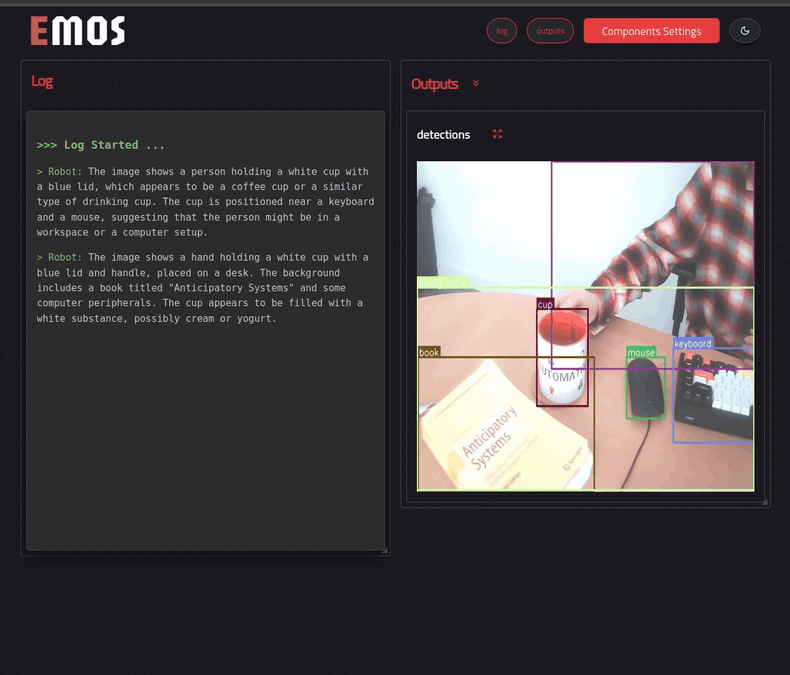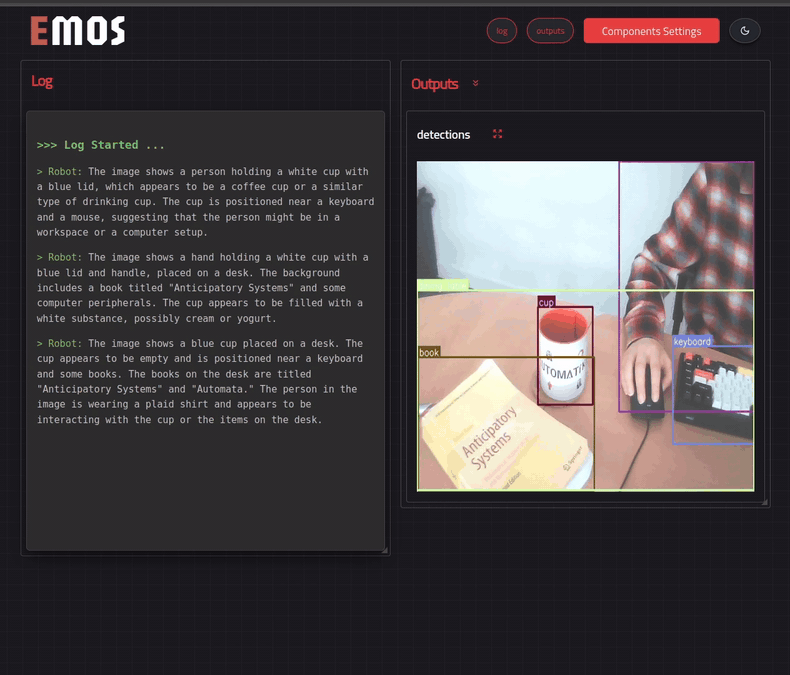
See the results in the UI¶
We can see this recipe in action if we enable the UI. We can do so by simply adding the following line in the launcher.
launcher.enable_ui(outputs=[camera_image, detections, description_output])
Note
In order to run the client you will need to install FastHTML and MonsterUI with
pip install python-fasthtml monsterui
The client displays a web UI on http://localhost:5001 if you have run it on your machine. Or you can access it at http://<IP_ADDRESS_OF_THE_ROBOT>:5001 if you have run it on the robot.
In the screencast below, we have replaced the event triggering label from person with cup for demonstration purposes.
Complete Code¶
Here is the complete recipe for the Event-Driven Visual Description agent:
1from agents.components import Vision, VLM
2from agents.config import VisionConfig
3from agents.clients import OllamaClient
4from agents.models import OllamaModel
5from agents.ros import Launcher, Topic, FixedInput, Event
6
7# Define Topics
8camera_image = Topic(name="/image_raw", msg_type="Image")
9detections = Topic(name="/detections", msg_type="Detections") # Output of Vision
10description_output = Topic(name="/description", msg_type="String") # Output of VLM
11
12# Setup the Vision Component (The Trigger)
13# We use a lower threshold to ensure we catch people easily and we use a small local model
14vision_config = VisionConfig(threshold=0.6, enable_local_classifier=True)
15
16vision_detector = Vision(
17 inputs=[camera_image],
18 outputs=[detections],
19 trigger=camera_image, # Runs on every frame
20 config=vision_config,
21 component_name="eye_detector",
22)
23
24# Define the Event
25# This event listens to the 'detections' topic.
26# It triggers ONLY if the "labels" list inside the message contains "person"
27# after not containing a person (within a 5 second interval).
28event_person_detected = Event(
29 detections.msg.labels.contains_any(["person"]),
30 on_change=True, # Trigger only when a change has occurred to stop repeat triggering
31 keep_event_delay=5, # A delay in seconds
32)
33
34# Setup the VLM Component (The Responder)
35# This component does NOT run continuously. It waits for the event.
36
37# Setup a model client for the component
38qwen_vl = OllamaModel(name="qwen_vl", checkpoint="qwen2.5vl:7b")
39ollama_client = OllamaClient(model=qwen_vl)
40
41
42# We define a fixed prompt that is injected whenever the component runs.
43fixed_prompt = FixedInput(
44 name="prompt",
45 msg_type="String",
46 fixed="A person has been detected. Describe their appearance briefly.",
47)
48
49visual_describer = VLM(
50 inputs=[fixed_prompt, camera_image], # Takes the fixed prompt + current image
51 outputs=[description_output],
52 model_client=ollama_client,
53 trigger=event_person_detected, # CRITICAL: Only runs when the event fires
54 component_name="visual_describer",
55)
56
57# Launch
58launcher = Launcher()
59launcher.enable_ui(outputs=[camera_image, detections, description_output])
60launcher.add_pkg(
61 components=[vision_detector, visual_describer],
62 multiprocessing=True,
63 package_name="automatika_embodied_agents",
64)
65launcher.bringup()